
Shipping software for embedded devices has traditionally meant long release cycles, risky upgrades and “Big Bang” releases. But it doesn’t have to be that way. Being able to ship updates to your devices faster and more reliably can be a game-changer for your business. It means being able to ship earlier, respond to customer feedback more quickly, and fix bugs on the fly. When shipping software becomes a routine and safe, teams can focus on delivering value instead of managing risky releases. Moving from a few releases every odd year to a few releases every month will be a game-changer and it is not as hard as you might think.

As embedded devices store more and more sensitive data, encryption-at-rest becomes a critical requirement. Especially for devices that are publicly accessible or deployed in untrusted environments, protecting data while the device is powered down is essential. Together with secure boot, encryption at rest ensures that data stored on the device remains confidential and tamper-proof, even if the device is physically compromised. This article describes how to implement LUKS encryption for embedded Linux devices based on the Raspberry Pi Compute Module 4 using the yocto Project. (Warning, this is a long read!)

Security is no longer optional for embedded devices, especially not with the Cyber Resilience Act coming into effect. Unfortunately, adding secure boot to embedded Linux devices is often not straightforward. In this post, we share our experience implementing secure boot for an embedded Linux device based on the Raspberry Pi Compute Module 4 using the Yocto Project. (Warning, this is a long read!)
Der EU Cyber Resilience Act (CRA) wird zu einer wegweisenden Regulierung für Softwaresicherheit in Europa. Mit dem geplanten Inkrafttreten ab September 2026 müssen Unternehmen, die Software oder eingebettete Geräte entwickeln, seine Anforderungen erfüllen - sonst riskieren sie den Zugang zum EU-Markt zu verlieren. Das klingt zunächst einschüchternd, ist aber oft weniger überwältigend als gedacht. Dieser Beitrag bietet einen praxisnahen Überblick darüber, was der CRA verlangt, was Unternehmen etablieren müssen und wie sie Schritt für Schritt beginnen können.
How to handle errors in C++ has been a constant point of debate. Do you use exceptions, error code, out-parameters or return nullptrs on failure? And how do you convey information on the nature of the failure? With C++17 we got std::optional for “value or nothing” semantics, but it lacks error context. C++23 - finally - introduces std::expected, a type that encapsulates either a value or an error, making error handling explicit and composable. Let’s explore how std::expected can improve your C++ code.

Large Language Models (LLMs) and AI agents are everywhere and there are tons of online services that let you use them. But what if you want to build your own, local AI agent that can run on your own hardware, without relying on cloud services? No problem - starting there is not as difficult as one might think. There is a great open source project called llama.cpp that makes it easy to run LLMs on your own hardware. Let’s see how to get stated with a simple AI agent using llama.cpp, CMake and C++.

CI/CD pipelines are a standard part of many software development workflows. However, many teams still struggle with long build times, flaky tests and inefficient workflows. Apart from driving the cost of CI up, these issues can lead to frustration and reduced productivity up to quality issues as developers may not run the full test suites before deploying their changes. One approach to address these challenges is to use artifact based CI, which can significantly improve the efficiency and reliability of your CI/CD pipelines.
“CMake is hard and our builds are a nightmare!” If that sounds familiar, you’re not alone. CMake has a reputation for being painful to use - but most of that pain comes from bad practices, not the tool itself.In this post, I’ll break down 7 of the most common CMake anti-patterns I see in real projects. These issues often creep in from legacy setups or lack of modern CMake knowledge, and they tend to slow teams down, cause frustration, and make build systems nearly unmaintainable.
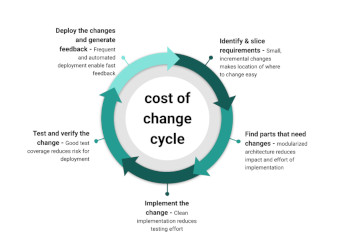
Software development is an expensive business. Measured over the lifespan of a product, the cost of maintaining and changing the code over time often greatly outweighs the initial development cost. Successful software products nowadays often have lifespans measured in decades rather than years, and often they are kept under active development throughout the whole period. Evolving technology, fixing defects, adaptation to customer needs, or pressure from competition are common reasons why software needs change. In view of this, it is paramount that when designing software and writing code, you should optimize for reducing future cost of change first before anything else.
Managing dependencies in CMake is hard. It’s a common pain point for C++ developers, especially when working on multi-platform projects or with complex dependencies. The introduction of dependency providers in CMake 3.24 aims to simplify this process by allowing package managers like Conan to provide dependency information directly to CMake. Conan and CMake are already a powerful combination for managing C++ dependencies, and this new feature further enhances their integration. In this post, we’ll explore how to use Conan as a CMake dependency provider, making dependency management in CMake projects more seamless and efficient. A sample project can be found on my github account